Desktop Tool
While our pipeline works well for OCR of a corpus efficiently using cloud servers, it was hard to get the features of the pipeline on your own computer. So we spent a bit of time recently creating a new tool which is designed to run self- contained on a desktop computer. We’re calling the tool rescribe, because why not? At the moment it’s a command line only tool.
We recently recorded a 5 minute lightning talk about the tool, if you’re interested to learn a little more and see it in action before trying it yourself.
Install dependencies
rescribe is a part of our bookpipeline package, and we provide pre built executables for it which can be downloaded for each platform here - save them to wherever you want to run the program from:
Next, you need to install the Tesseract OCR engine, which the tool uses for the core OCR step. If you’re on Linux this should be available from your package manager, follow these instructions if you’re on a Mac, or download and run an installer from this page for Windows.
Finally, you will need to download an OCR training set for the language / script you’re interested in. We provide trainings for Caroline Miniscule, early printed Latin and Ancient Greek. Any other Tesseract OCR training set will also work fine.
Usage
Still here? Great. Now open up a terminal window. Don’t worry, it will be worth it. If you’re on Windows, you can type cmd.exe into the run box, on OSX it’s under Applications -> Utilities -> Terminal, and if you’re on Linux I bet you already know where to find your terminal.
Firstly, if you’re on Linux or OSX you will probably need to make
the program executable after downloading it, so do that now by
running chmod +x rescribe. You’ll only have to do that once.
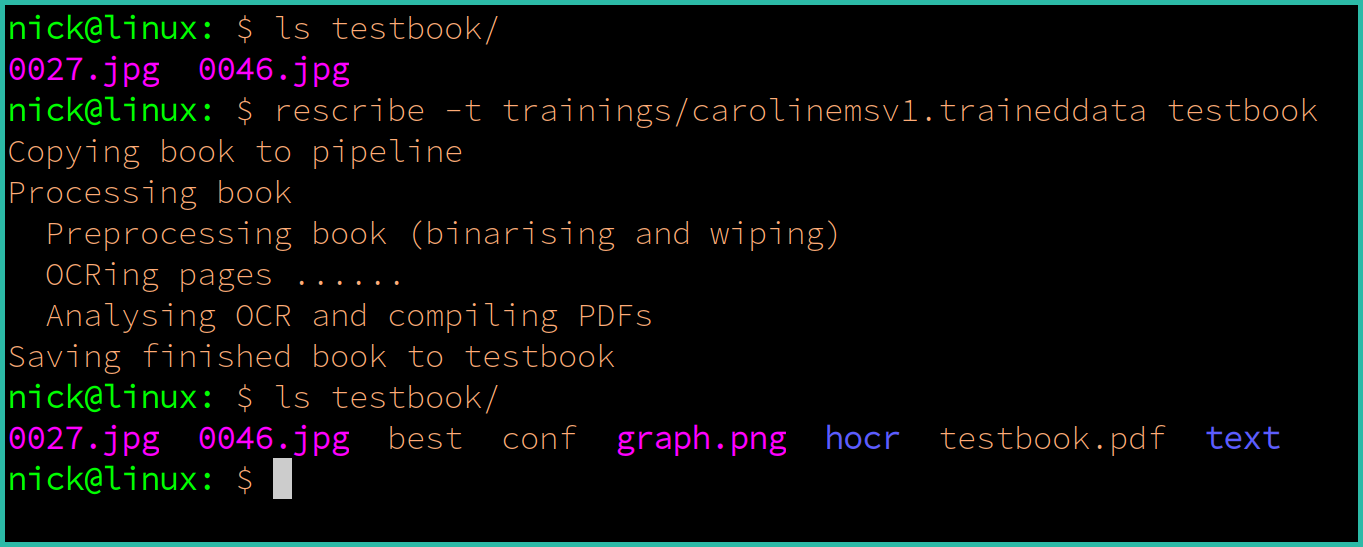
You use rescribe by giving it the path of a training file to use and the directory containing the book or manuscript pages you want to OCR. Basic usage looks like this:
./rescribe -t ../trainings/carolinems.traineddata mybook
This will run rescribe with a training at ../trainings/carolinems.traineddata over all pages in the directory mybook. A successful run will add several new files to mybook:
- A PDF file named after the directory (
mybook.pdfin the above example), which is fully searchable. - A
textdirectory, containing plain text versions of the OCR results for each page. - A
hocrdirectory, containing hOCR formatted OCR results for each page. - A
graph.pngfile, which shows the OCR confidence of each page (a rough indicator of the quality of the OCR over the book). - A
conffile, which lists the OCR confidence of each page, at each preprocessing binarisation threshold attempted.
Limitations
One limitation at the moment is that rescribe is very sensitive
to how page images are named. It will only work on pages named
<anything>0001.png or <anything>0001.jpg, where 0001 is any
four digit number (and <anything> is anything!).
There are likely to be bugs! Let us know of any issues you have, any features you’d like, or just that you’re enjoying using it!